使用Python解析Wav文件
音频文件及代码已经放在GitHub上了
Wav文件格式
Waveform Audio File Format(WAVE,又或者是因为扩展名而被大众所知的WAV),是微软与IBM公司所开发在个人电脑存储音频流的编码格式,在Windows平台的应用软件受到广泛的支持,地位上类似于麦金塔电脑里的AIFF。此格式属于资源交换档案格式(RIFF)的应用之一,通常会将采用脉冲编码调制的音频资存储在区块中。也是其音乐发烧友中常用的指定规格之一。由于此音频格式未经过压缩,所以在音质方面不会出现失真的情况,但档案的体积因而在众多音频格式中较为大。通常使用三个参数来表示声音,量化位数,取样频率和采样点振幅。量化位数分为8位,16位,24位三种,声道有单声道和立体声之分,单声道振幅数据为n*1矩阵点,立体声为n*2矩阵点,取样频率一般有11025Hz(11kHz) ,22050Hz(22kHz)和44100Hz(44kHz) 三种。
WAV文档遵守资源交换档案格式之规则,在文件的前44(或46)字节放置标头(header),使播放器或编辑器能够简单掌握文件的基本信息,其内容以区块(chunk)为最小单位,每一区块长度为4字节,而区块之上则由子区块包裹,每一子区块长度不拘,但须在前头先宣告标签及长度(字节)。标头的前3个区块日志案格式及长度;接着第一个子区块包含8个区块,记录声道数量、采样率等信息;接着第二个子区块才是真正的音频数据,长度则视音频长度而定。内容如下表所示。须注意的是,每个区块的端序不尽相同,而音频内容本身则是采用小端序。
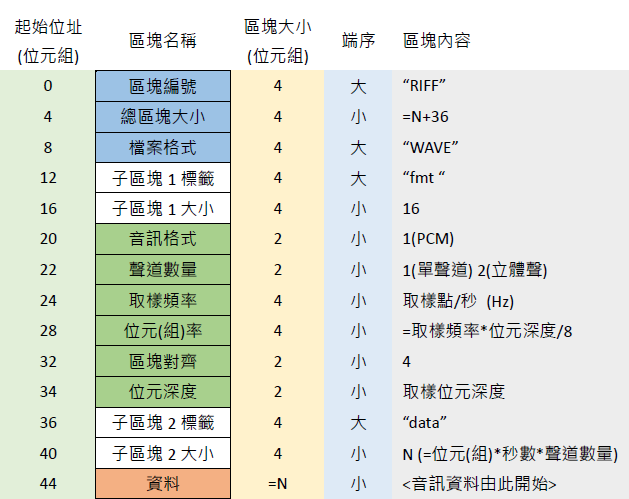
DATA块内的信息是根据format chunk内的信息而决定的.由量化位数/声道数/采样率共同决定,下图为四种情况下DATA区域存储信息的格式:

Python读取WAV文件的信息
- Python自带的Wave库中集成了许多函数,可以打开WAV文件并读出所需要的数据。
- 可以使用
wave.open(file,[mode])打开WAV文件,'r','rb'是只读格式,'w','wb'是只写模式。 - 使用Wave库中自带的
Wave_read.getparams()方法可以读取到WAV文件的参数,返回的参数是一个元组(nchannels, sampwidth, framerate, nframes, comptype, compname)
- 可以使用
- 也可以使用scipy.io.wavfile中的
read("filename",mmap)返回的值是rate: int , data:numpy array较上一个方法比较简便的是不用再使用numpy.fromstring,numpy.shape,numpy.T等方法对数据进行操作转换成绘图所需要的格式
使用Numpy和Matplotlib来进行波形图的绘制
步骤如下
- 通过wav库获得WAV文件的头文件中的信息,如采样率/声道数等等.
- 提取出DATA区域的信息,用Numpy将string格式数据转化为数组
- 通过判定声道数将DATA区域数据进行处理(对数组矩阵进行转换)
- 得到每个绘制点的时间(x坐标)
- 用Matplotlib库的Pyplot API 提供的方法绘制出波形图
代码如下
1 | import wave as we |
使用网上下载的test.wav文件并绘制波形


可以发现这个WAV文件的左右声道波形完全不一样,说明这是个立体声双声道音频文件。
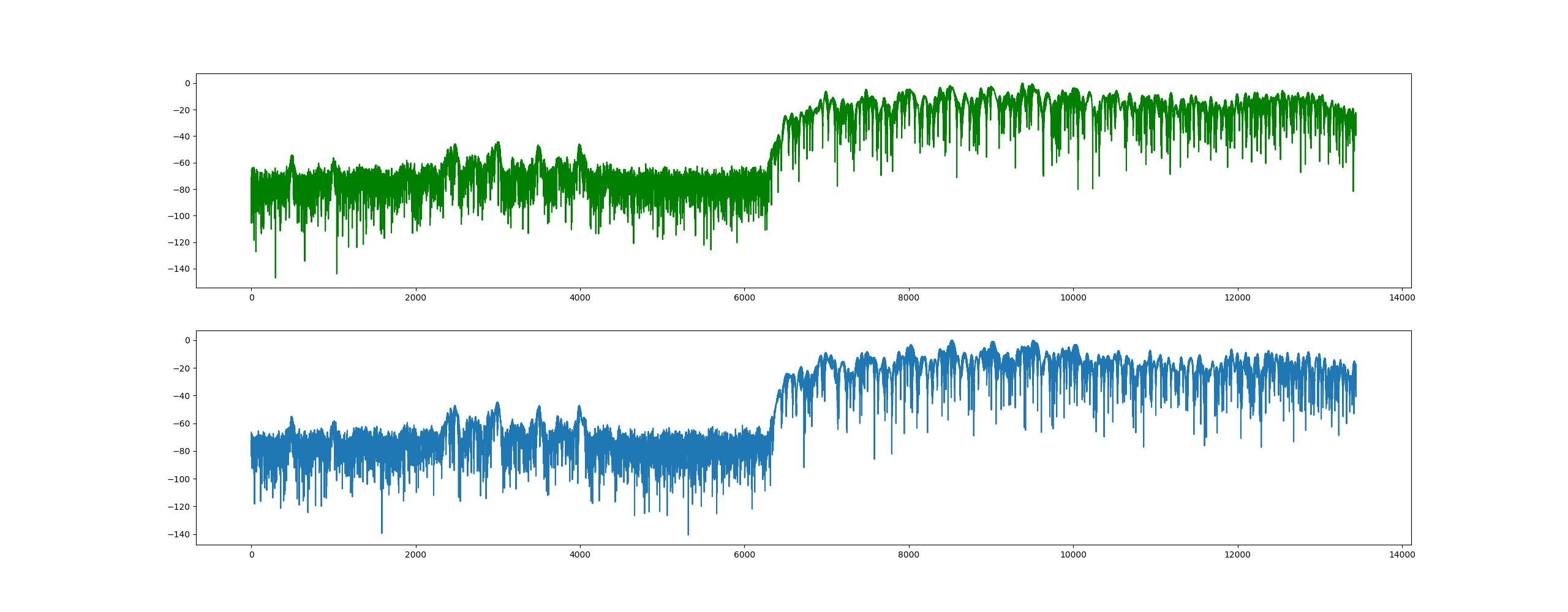
通过查阅scipy的文档,发现了一个specgram函数,可以直接绘制WAV文件的语音频谱图,语音频谱图的横坐标是时间,纵坐标是频率,坐标点值为语音数据能量,因而语音频谱图很好的表达了语音的音色随时间变化的趋势。有些经验丰富的人能够通过看语谱图而知道对应的语音信号的内容, 这种技术成为Spectrogram Reading。
绘制的波形图和语音频谱图如下:
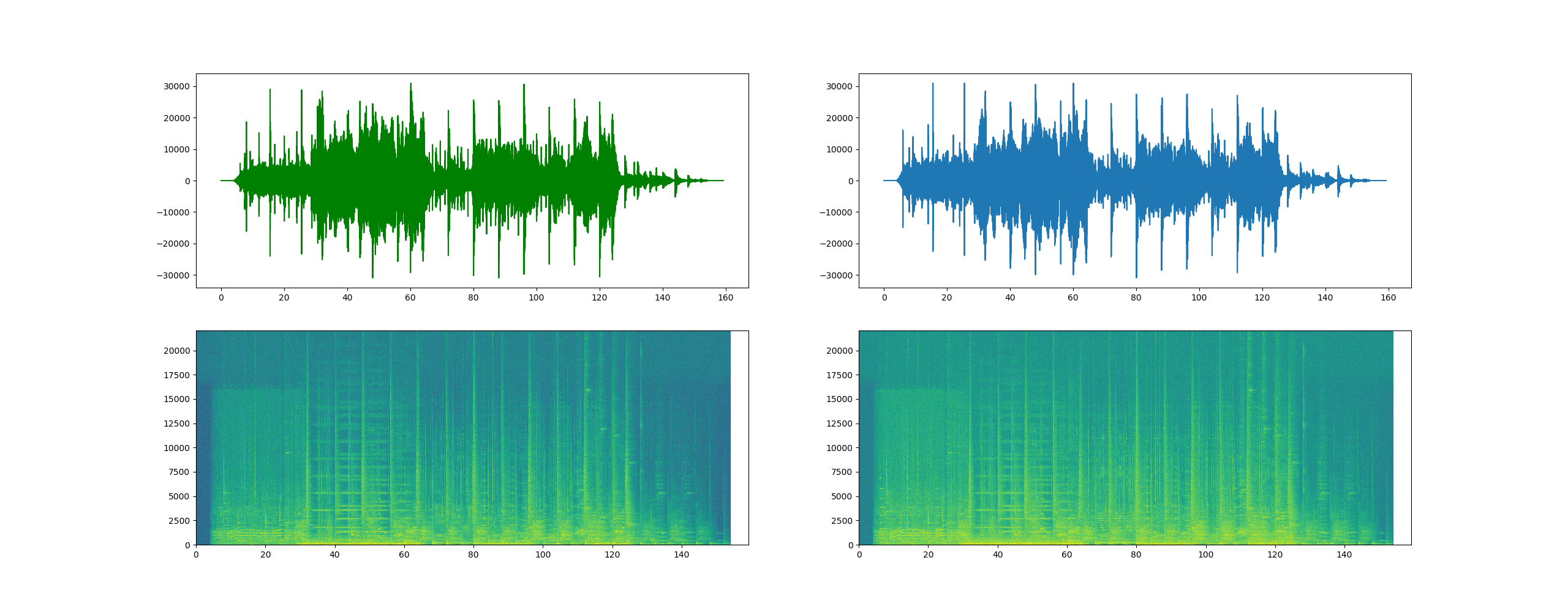
使用自己手机录制的WAV文件进行绘图

图中的波形是录制的“啊”的声音波形。
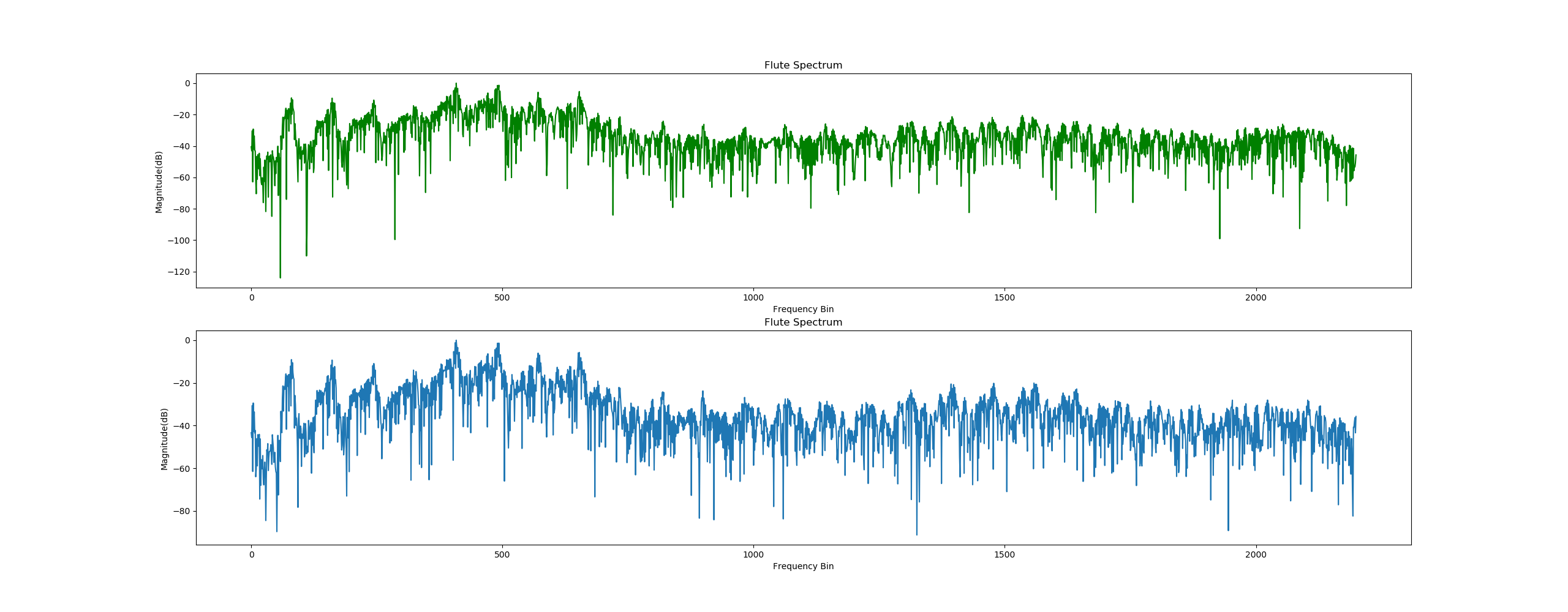
使用Numpy、Scipy和matplotlib来绘制频谱图
代码如下:
1 | import wave as we |
使用test.wav文件绘制的频谱图如下:
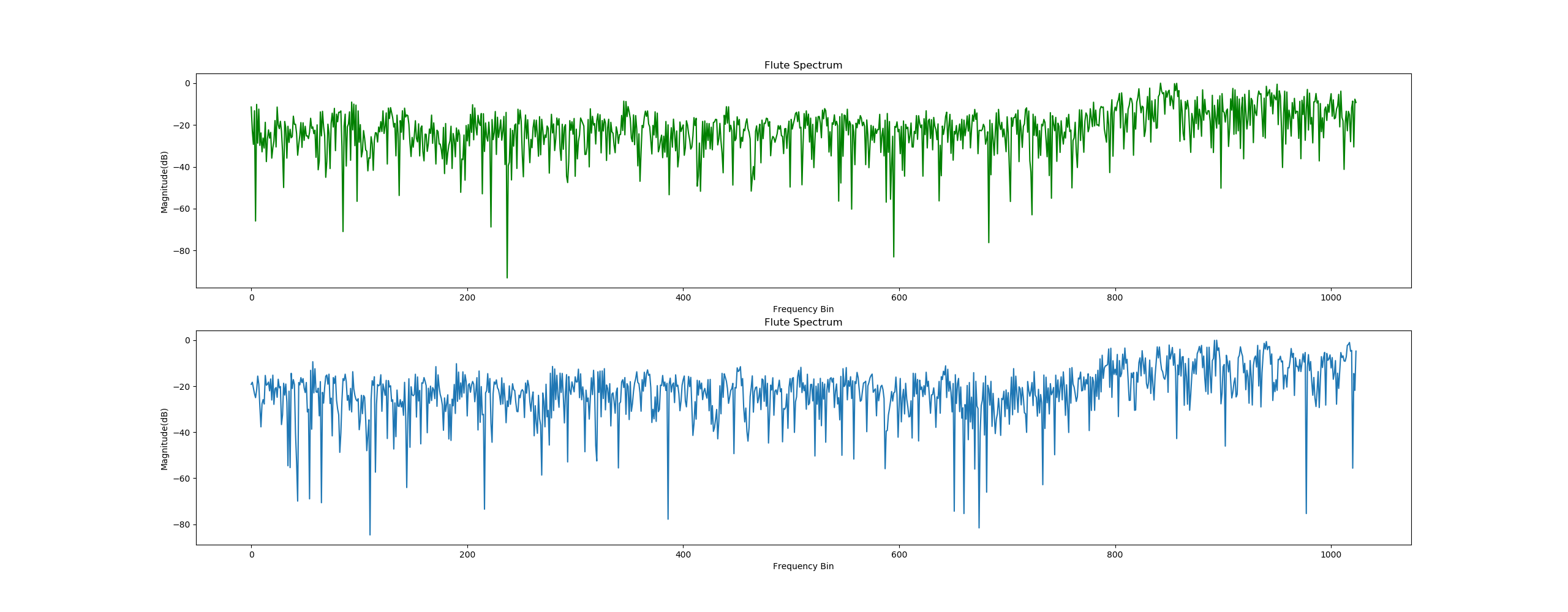
使用自己录制的WAV文件绘制的频谱图如下:
使信号通过数字滤波器
数字滤波器
数字滤波器是对数字信号进行滤波处理以得到期望的响应特性的离散时间系统。作为一种电子滤波器,数字滤波器与完全工作在模拟信号域的模拟滤波器不同。数字滤波器工作在数字信号域,它处理的对象是经由采样器件将模拟信号转换而得到的数字信号。数字滤波器具有比模拟滤波器更高的精度,甚至能够实现后者在理论上也无法达到的性能。例如,对于数字滤波器来说很容易就能够做到一个1000Hz的低通滤波器允许999Hz信号通过并且完全阻止1001Hz的信号,模拟滤波器无法区分如此接近的信号。由于奈奎斯特采样定理(Nyquist sampling theorem),数字滤波器的处理能力受到系统采样频率的限制。如果输入信号的频率分量包含超过滤波器1/2采样频率的分量时,数字滤波器因为数字系统的“混叠”而不能正常工作。如果超出1/2采样频率的频率分量不占主要地位,通常的解决办法是在模数转换电路之前放置一个低通滤波器(即抗混叠滤波器)将超过的高频成分滤除。否则就必须用模拟滤波器实现要求的功能。
设计数字滤波器
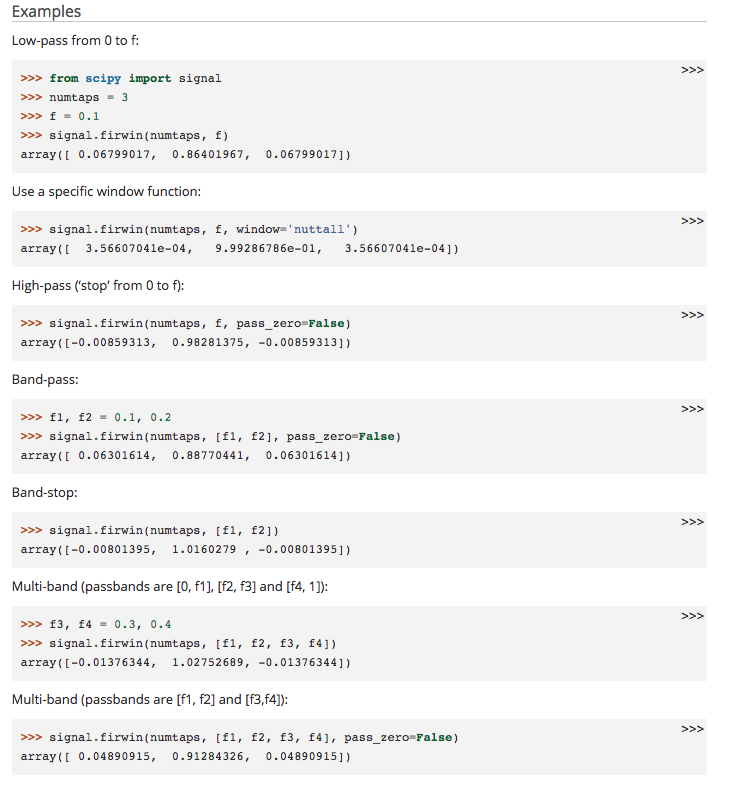
可以使用scipy.signal包中的firwin(),firwin2()函数来进行FIR滤波器的设计。
可以参考Scipy.Signal.Firwin()的官方文档来设计滤波器,官方文档上也给出了很多滤波器的例子,如下图所示:
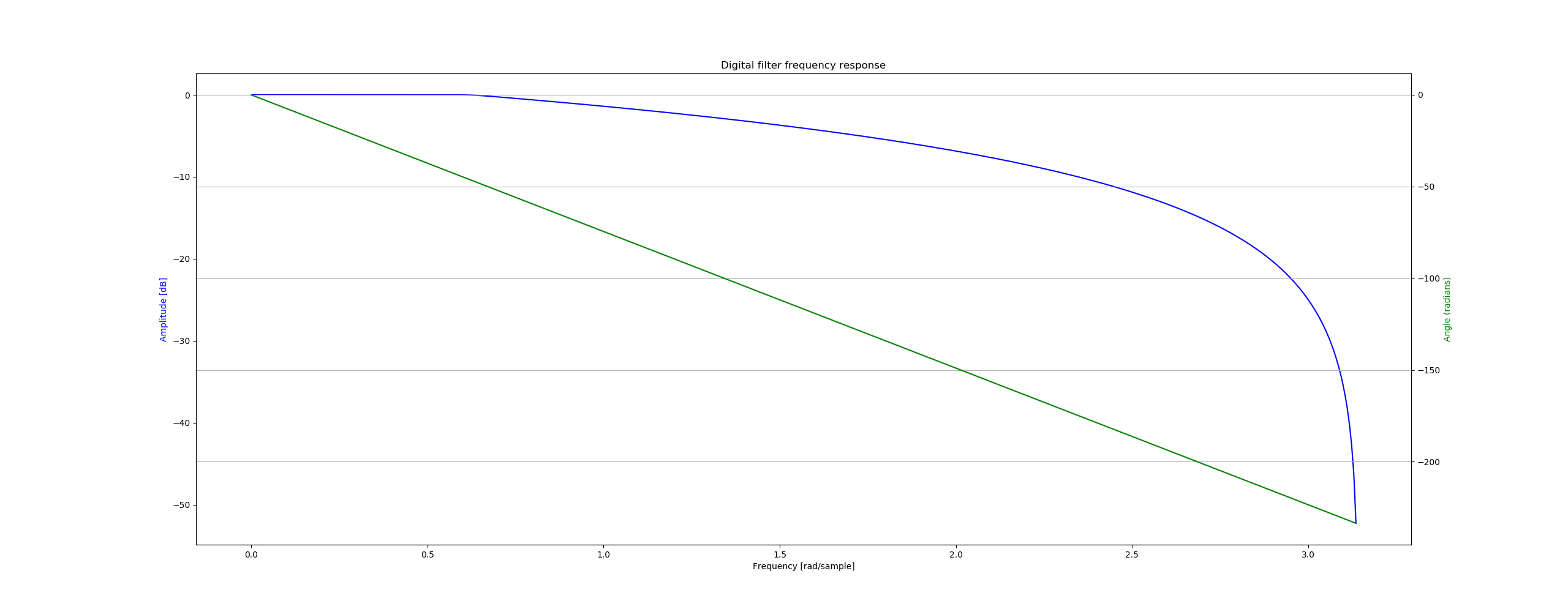
使用Hann窗滤波器
Hann窗函数低通滤波器的频率响应图和相位图如下所示:
将WAV的数据文件转换成Numpy中的Array后和滤波器进行卷积,numpy.convolve()方法可以实现信号和滤波器的卷积,经过滤波后的结果如图
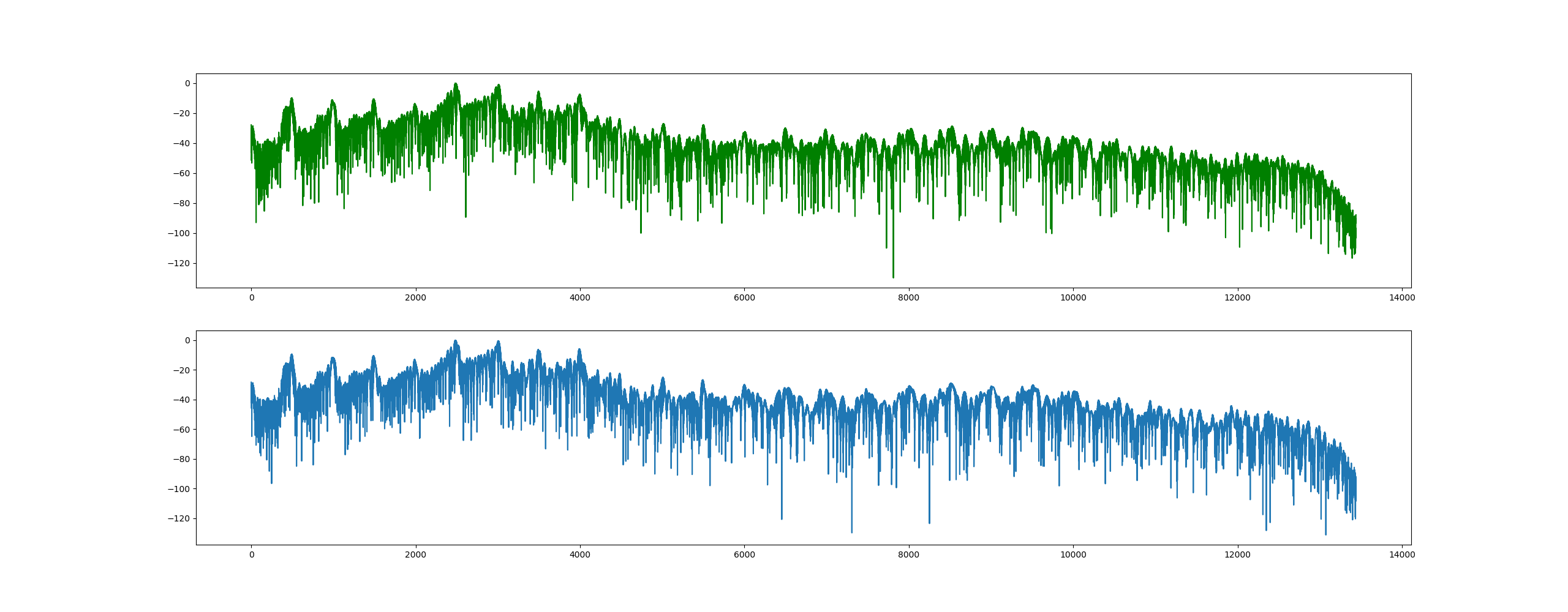
与未经过滤波器的波形相对比,可以发现高频部分有一定程度的衰减。
使用Kaiser窗滤波器
Kaiser窗高通滤波器的频率响应和相位图如下图所示: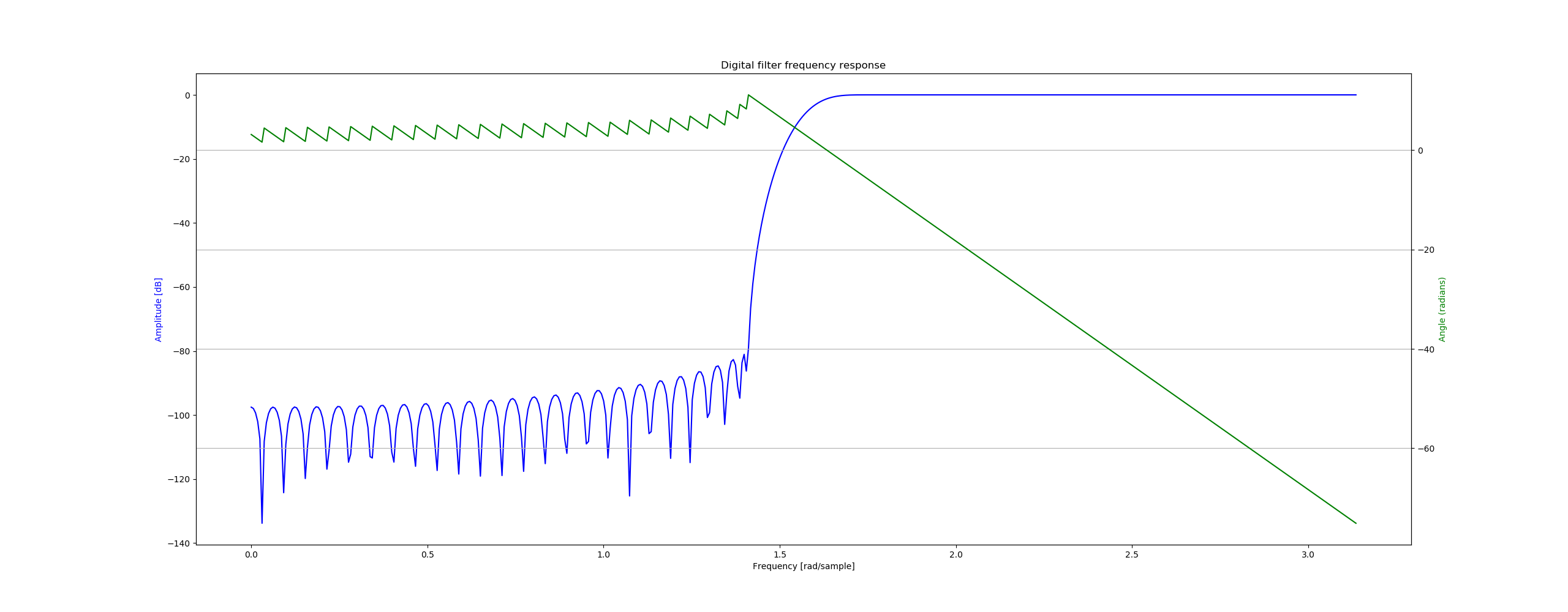
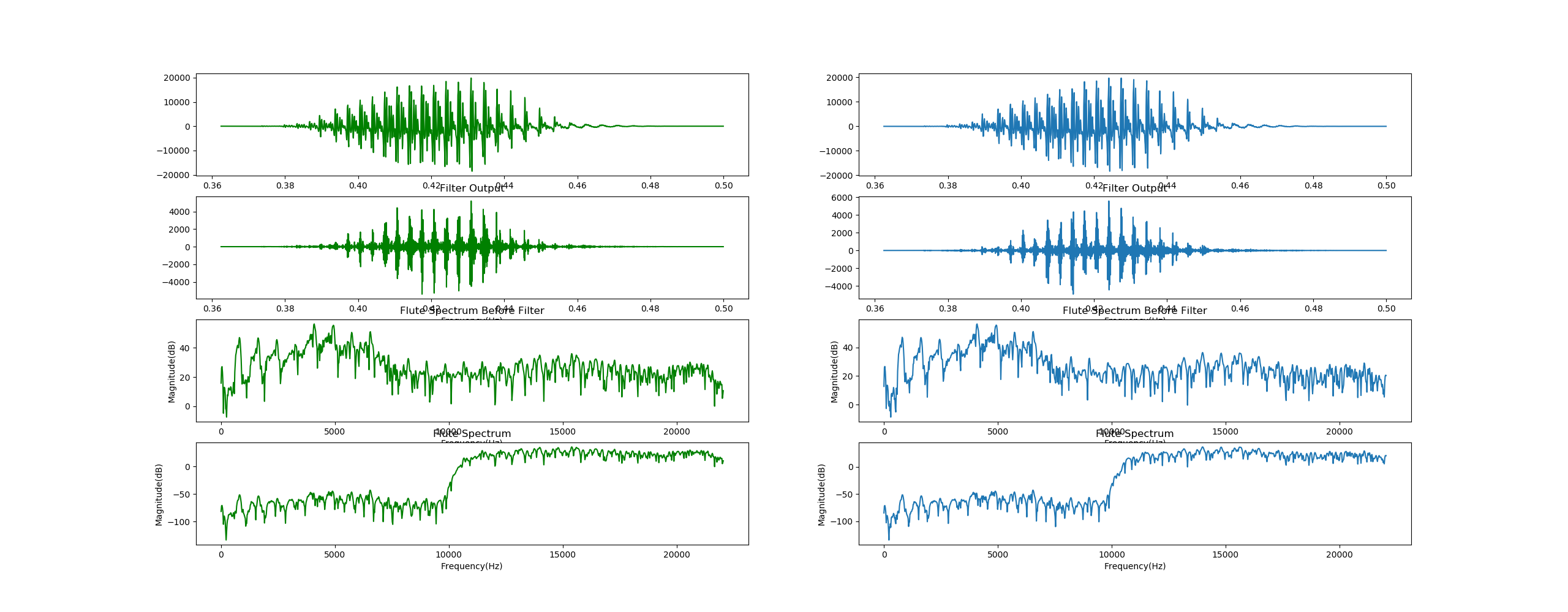
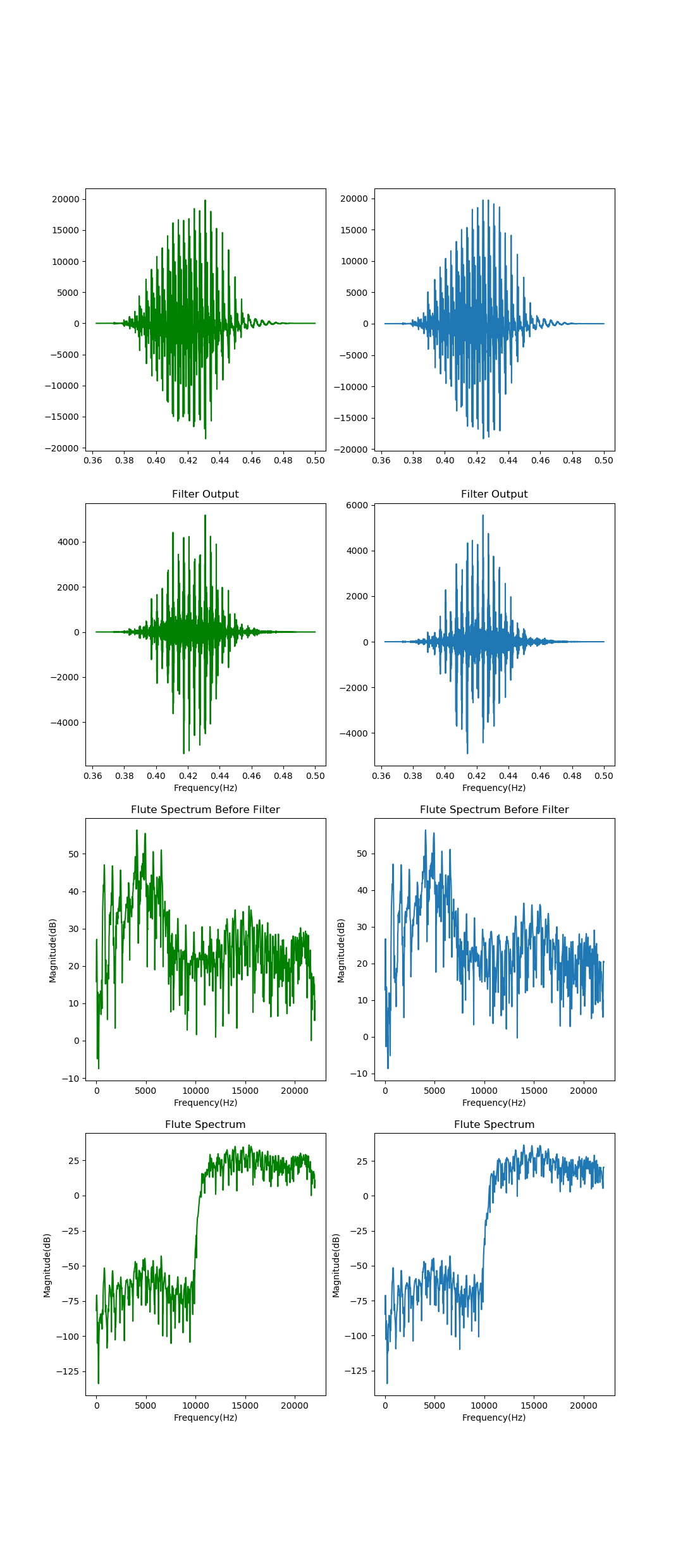
将WAV文件的数据信号与滤波器进行卷积,经过滤波后的结果如图所示范:
可以很明显的看到,低频部分的信号被极大程度的衰减,可以说是成功完成了滤波。
代码如下
1 | import wave as we |
绘图
左侧为左声道信号,右侧为右声道信号
- 第一行所示图片为原始信号
- 第二行所示图片为经过滤波器后得到的信号
- 第三行所示图片为原始信号的频域图
- 第四行所示图片为经过滤波器后信号的频域图
参考
- 频域信号处理-用Python做科学计算
- Python解析WAV文件并绘制波形的方法 xlxw‘s blog
- Numpy Reference
- Scipy Reference
- Matplotlib Pyplot API
- Python For Audio Signal Processing by John GLOVER, Victor LAZZARINI and Joseph TIMONEY. The Sound and Digital Music Research Group National University of Ireland, Maynooth Ireland. {John.C.Glover, Victor.Lazzarinig}@nuim.ie JTimoney@cs.nuim.ie